Overview
This page aims to demonstrate the capabilities of the well-known Bidirectional Encoder Representation from Transformers (BERT) model with two Bidirectional-LSTM layers, a fully connected layer, a drop out layer, and a classification layer for a classification task, specifically the popular Kaggle Competition Natural Language Processing with Disaster Tweets. The use of this architecture resulted in achieving a top 4% score on the leaderboard. To further illustrate the reliability of this model's predictions, we will present 10 randomly selected predictions, and explain their how did the model decided to their class using Local Interpretable Model-Agnostic Explanations (LIME).
Introduction
In the pursuit of finding a model that achieved a top 4% score for the Kaggle's Natural Language Processing with Disaster Tweets competition, we conducted a search. The dataset utilized in this competition is a CSV file containing an id column, which serves as a unique identifier for each tweet, a text column with the tweet's text, and several other columns not utilized in the training process. Further information regarding the dataset can be found in the "Data" section of the competition's page. It is worth noting that the discussion on this page pertains specifically to the training dataset.
The current dataset consists of 7613 tweets, with a range in length from 1-31 words, and a character count range of 7-157 characters. These tweets also may contain hashtags, mentions, and links. The tweets are classified into two categories: real disaster and not real disaster, with the distribution as follows:
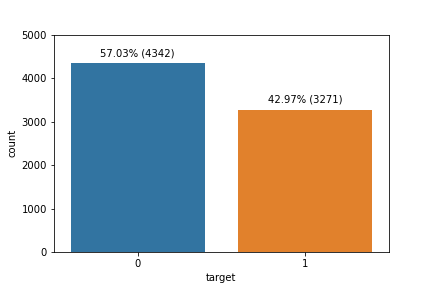
Below, we can see the n-grams for both classes. An N-gram is a group of N consecutive words (three in Figure 2) that can be either a long chunk of text or a shorter collection of syllables. N-Gram models utilize sequence data as input and generate a probability distribution of all potential items. From this distribution, a prediction is made based on the likelihood of each item. In addition to next-word prediction, N-Grams can also be utilized in language identification, information retrieval, and DNA sequencing predictions.
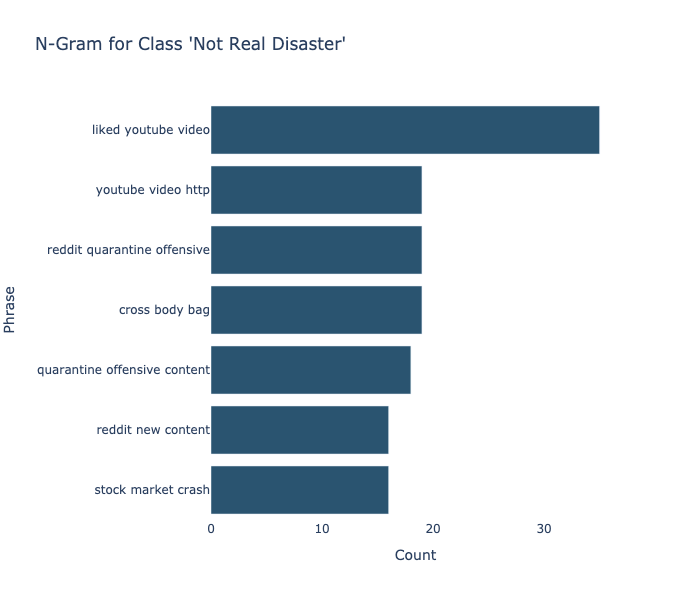
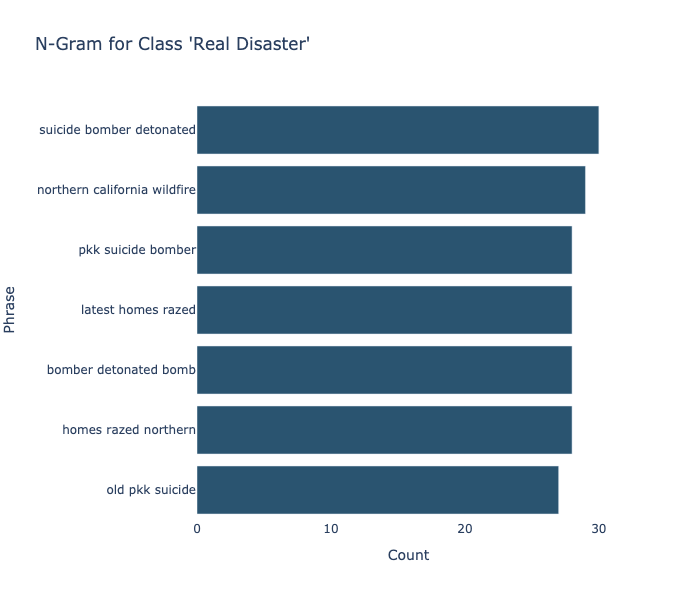
To classify the dataset, we employed the use of Bidirectional Encoder Representations from Transformers (BERT). BERT is a model that has been designed to achieve state-of-the-art results upon fine-tuning on various tasks including classification, question answering, and language inference. In the design of a language model, it is crucial to consider the tasks the model will be attempting to perform. In the case of BERT, the model is attempting to predict masked tokens as well as determining whether sentence B subsequent to sentence A. For a more comprehensive understanding of this model, one can refer to the original research paper.
Model Architecture
The pre-trained BERT model can be fine-tuned with the addition of a single output layer. However, in our case, a more complex architecture was chosen. First, the text was tokenized and masked as described in the original paper, and then the sequence output of the model was captured and fed into a bidirectional-LSTM layer with 1024 units and a dropout rate of 90%. This layer produced a sequence output, which was then fed into another bidirectional-LSTM layer with the same hyperparameters. The pooled output of the later layer was passed through a dense layer with 64 hidden units and a ReLU activation function, followed by a dropout layer with a rate of 20%. Finally, the weights were passed to the output layer, which contained two units and utilized the Softmax activation function.
For this model, the uncased large BERT model from TensorFlow Hub was utilized, featuring 24 Transformer blocks, a hidden size of 1024, and 16 Attention Heads. Additionally, the output layer used two units and a Softmax activation function rather than a single unit and a Sigmoid activation function, allowing for the use of the model's predict method in Local Interpretable Model-Agnostic Explanations (LIME).
Explain Sample Tweets
The subsequent carousel displays a number of randomly selected samples in which the model attempts to predict the class of the tweets. For each sample, the original tweet, the top words that influenced the model's decision, the predicted and true labels of the tweet are presented.
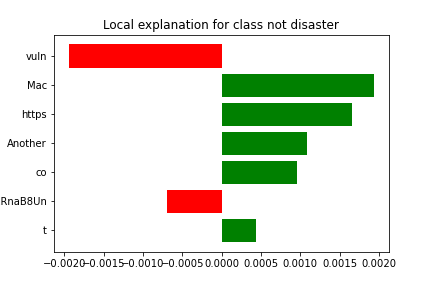
Tweet: Another Mac vuln!\n\nhttps://t.co/OxXRnaB8Un
It appears that the model classified this tweet due to the presence of phrases such as "vuln", and the a few latters in the link; "OxXRnaB8Un" which influenced the decision-making process. Additionally, the model's prediction appears to have been made with some uncertainty, as indicated by the presence of words such as "Another", and "Mac".
True Class: Not real disaster
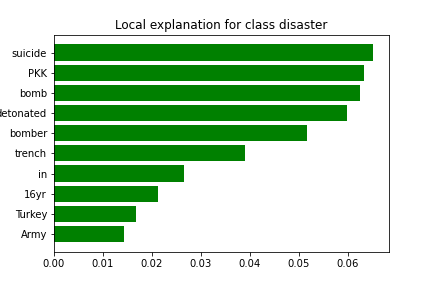
Tweet: Pic of 16yr old PKK suicide bomber who detonated bomb in Turkey Army trench released http://t.co/FVXHoPdf3W
It appears that the model classified this tweet correctly with 100% certainty.
True Class: Disaster
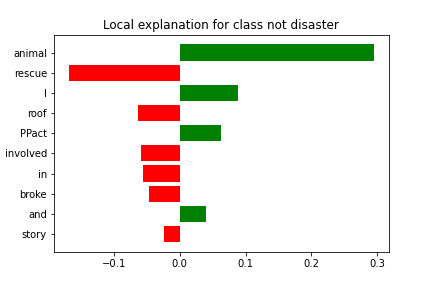
Tweet: I'm on 2 blood pressure meds and it's still probably through the roof! Long before the #PPact story broke I was involved in animal rescue
It appears that the model classified this tweet correctly due to the presence of phrases such as "rescue", "roof", and "involved" which influenced the decision-making process. Additionally, the model's prediction appears to have been made with some uncertainty, as indicated by the presence of words such as "animal", and "I".
True Class: Not real disaster

Tweet: @realDonaldTrump to obliterate notion & pattern political style seemly lead voter beliefs Sarcasm Narcissism #RichHomeyDon #Swag #USA #LIKES
It appears that the model classified this tweet correctly due to the presence of phrases such as "political", "obliterate", and "beliefs" which influenced the decision-making process. Additionally, the model's prediction appears to have been made with some uncertainty, as indicated by the presence of words such as "LIKES", and the mention "realDonaldTrump".
True Class: Not real disaster
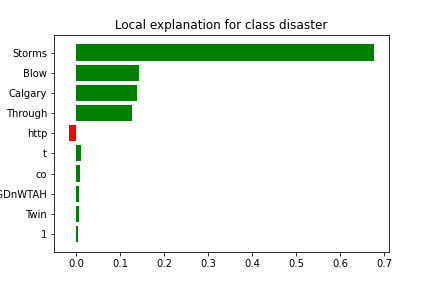
Tweet: Medieval airplane hijacker hard shell: casting the star deviating: dYxTmrYDu
It appears that the model has misclassified this tweet due to the presence of phrases such as "star", "hard", and "casting" which influenced the decision-making process. Additionally, the model's prediction appears to have been made with some uncertainty, as indicated by the presence of words such as "hijacker", and "airplane".
True Class: Disaster
Tweet: # handbags Genuine Mulberry Antony Cross Body Messenger Bag Dark Oak Soft Buffalo Leather: å£279.00End Date: W... http://t.co/FTM4RKl8mN
It appears that the model classified this tweet correctly due to the presence of phrases such as "W", "Cross", and "Buffalo" which influenced the decision-making process. Additionally, the model's prediction appears to have been made with some uncertainty, as indicated by the presence of other phrases such as "handbags", and "Soft".
True Class: Not real disaster
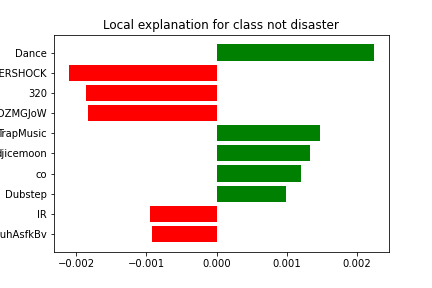
Tweet: 320 [IR] ICEMOON [AFTERSHOCK] | http://t.co/M4JDZMGJoW | @djicemoon | #Dubstep #TrapMusic #DnB #EDM #Dance #Ices\x89Û_ http://t.co/n0uhAsfkBv
It appears that the model classified this tweet correctly due to the presence of phrases such as "AFTERSHOCK", "320", and the links which influenced the decision-making process. Additionally, the model's prediction appears to have been made with some uncertainty, as indicated by the presence of phrases such as "Dance", and "TrapMusic".
True Class: Not real disaster
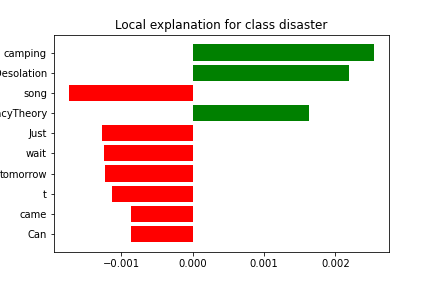
Tweet: Just came back from camping and returned with a new song which gets recorded tomorrow. Can't wait! #Desolation #TheConspiracyTheory #NewEP
It appears that the model misclassified this tweet due to the presence of phrases such as "song", "wait", and "Just" which influenced the decision-making process. Additionally, the model's prediction appears to have been made with some uncertainty, as indicated by the presence of words such as "camping", and the hashtags. Notice however, reading the tweet, it does not sound like a disaster, and thus we believe the model classified it correctly, and the label is incorrect.
True Class: Disaster
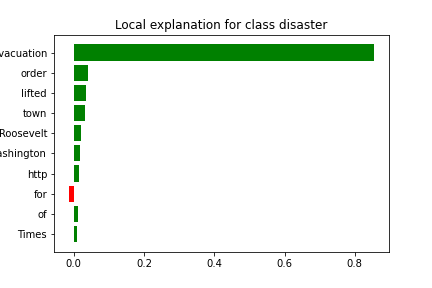
Tweet: Evacuation order lifted for town of Roosevelt - Washington Times http://t.co/Kue48Nmjxh
It appears that the model classified this tweet correctly mostly due to the presence of the phrases such as "Evacuation" which influenced the decision-making process.
True Class: Disaster
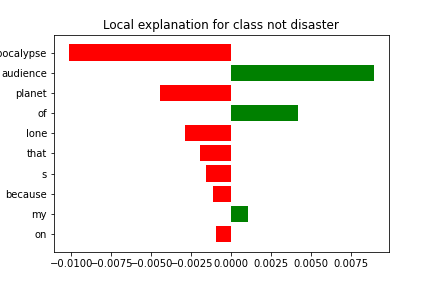
Tweet: And that's because on my planet it's the lone audience of the apocalypse!
It appears that the model classified this tweet correctly due to the presence of phrases such as "apocalypse", "planet", and "lone" which influenced the decision-making process. Additionally, the model's prediction appears to have been made with some uncertainty, as indicated by the presence of words such as "audience", and "of".
True Class: Not real disaster
Conclusion
Upon analyzing the model's predictions on a selection of randomly chosen tweets, we can consider this model to be a reliable tool for this task. To further increase the reliability of the model, we recommend removing URLs from the tweets as a potential strategy.